数据库编码格式问题的全面解决方案
数据库编码格式问题的全面解决方案
数据库编码格式不一致或设置错误,是导致数据乱码、存储异常和跨平台/跨系统数据传输失败的常见根源。无论是MySQL、PostgreSQL还是SQL Server,正确处理编码问题对于保障数据完整性、应用稳定性和系统兼容性至关重要。本文将系统地探讨服务器数据库编码格式问题的成因、诊断方法与解决方案。
一、 问题成因:为何会出现编码格式问题?
- 环境不匹配:服务器操作系统、数据库软件、客户端连接工具以及应用程序可能使用不同的默认字符集(如UTF-8, GBK, Latin1等)。
- 配置不一致:数据库服务在安装、初始化或后续配置时,未统一设置字符集(
character<em>set</em>server,collation_server)和校对规则。 - 建库建表疏忽:创建数据库或数据表时,未显式指定字符集,继承了可能不合适的服务器默认设置。
- 连接层问题:客户端与服务器建立连接时,使用的连接字符集(如MySQL的
character<em>set</em>client,character<em>set</em>connection)与服务器或数据库的实际字符集不符。 - 数据迁移或导入导出:在不同字符集的数据库间迁移数据,或通过脚本、工具导入/导出数据时,未进行正确的字符集转换。
二、 诊断步骤:如何定位编码问题?
- 检查当前设置:
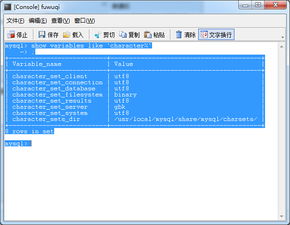
- MySQL: 使用SQL命令
SHOW VARIABLES LIKE 'character<em>set</em>%';和SHOW VARIABLES LIKE 'collation_%';。
- PostgreSQL: 使用
\l查看数据库编码,SHOW server_encoding;查看服务器编码。
- SQL Server: 查看数据库属性中的“排序规则”设置。
- 检查数据库与表结构:
- 查看特定数据库和表的创建语句(如
SHOW CREATE DATABASE db<em>name;,SHOW CREATE TABLE table</em>name;),确认其字符集定义。
- 测试数据读写:
- 插入包含多语言或特殊字符(如中文、Emoji)的测试数据,观察存储和读取是否正常。
- 审查连接与客户端:
- 检查应用程序连接字符串(如JDBC URL中的
characterEncoding参数)、命令行客户端的启动参数或配置。
三、 核心解决方案:统一与规范编码设置
最佳实践是全程使用 UTF-8(或对应的Unicode编码,如MySQL的utf8mb4),以最大化兼容性。
方案A:修改服务器全局配置(需重启,适用于新环境或彻底整改)
1. 修改配置文件:
* MySQL: 编辑 my.cnf (Linux) 或 my.ini (Windows),在 [mysqld] 部分添加:
`ini
[mysqld]
character-set-server=utf8mb4
collation-server=utf8mb4unicodeci
`
* PostgreSQL: 编辑 postgresql.conf,设置:
`ini
client_encoding = 'UTF8'
# 初始化集群时使用 --encoding=UTF8 更为彻底
`
- 重启数据库服务:使配置生效。
方案B:修改现有数据库、数据表与字段的编码(在线转换,适用于已有数据的环境)
重要:操作前务必对数据进行完整备份!
1. 修改数据库编码:
`sql
ALTER DATABASE your<em>database</em>name CHARACTER SET utf8mb4 COLLATE utf8mb4unicodeci;
`
2. 修改表编码:
`sql
ALTER TABLE your<em>table</em>name CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4unicodeci;
`
此命令会将表本身及其所有字符型字段的编码一并转换。
方案C:确保连接层编码一致
在应用程序的连接字符串或初始化代码中明确指定编码:
- JDBC示例 (MySQL):
jdbc:mysql://localhost:3306/db?useUnicode=true&characterEncoding=utf8&useSSL=false - Python (PyMySQL):
charset='utf8mb4'在connect参数中。
方案D:处理数据导入/导出
在使用 mysqldump, pg_dump 等工具时,使用 --default-character-set=utf8mb4 等参数确保导出文件的编码正确。导入时,也需确保目标数据库的编码设置兼容,并在导入命令中指定正确的字符集。
四、 高级场景与疑难处理
- “错码”数据的修复:如果已有数据因编码错乱而显示为乱码,情况可能比较复杂。通常需要先确认数据被“误读”和“误写”的编码转换路径,然后通过
CONVERT()或CAST()函数,或在导出、转换、再导入的过程中进行校正。这可能需要进行多次尝试和验证。 - 使用
utf8mb4而非utf8(针对MySQL):MySQL的utf8编码最大支持3字节,无法存储完整的Unicode字符(如Emoji)。utf8mb4(4字节)才是真正的全量UTF-8支持。建议将所有相关设置升级为utf8mb4。 - 云数据库或托管服务:原理相同,但修改配置的入口通常在云服务商的管理控制台,而非直接修改配置文件。请参考对应云服务的文档。
五、 预防措施
- 标准化与文档化:在项目初期,明确并文档规定所有环境、数据库、应用连接必须使用的字符集(强烈建议UTF-8系列)。
- 纳入部署流程:将数据库的初始化脚本(包含明确的
CHARACTER SET子句)纳入版本管理和自动化部署流程。 - 代码与配置审查:在代码审查中,检查数据库连接配置和ORM框架的字符集设置。
- 迁移预检查:在执行任何数据迁移前,先对比源端和目标端的字符集,并规划好转换步骤。
通过遵循以上诊断流程和解决方案,您可以系统地预防和修复绝大多数数据库编码格式问题,确保数据的准确性与服务的健壮性。记住,统一使用 UTF-8/utf8mb4 并确保各环节配置一致,是解决此类问题的黄金法则。
如若转载,请注明出处:http://www.doufen8.com/product/2.html
更新时间:2026-06-19 01:01:54